In this post I’m going to give a brief overview of how I manage my personal Fedora laptop, from installation to upgrades and backups. This is indeed not very original topic, but recently I discussed it with few people, and I realized that having a reference to a post like this will be useful. And maybe you will find some parts of it interesting.
Important assumption here is that that this approach is intended for a single desktop machine I both own and use. If I had to manage a fleet of desktops for other people, some choices here no longer makes sense.
OS Installation
First of all I need to install the operating system. I boot from Fedora KDE Plasma live image and from there start Fedora installer.
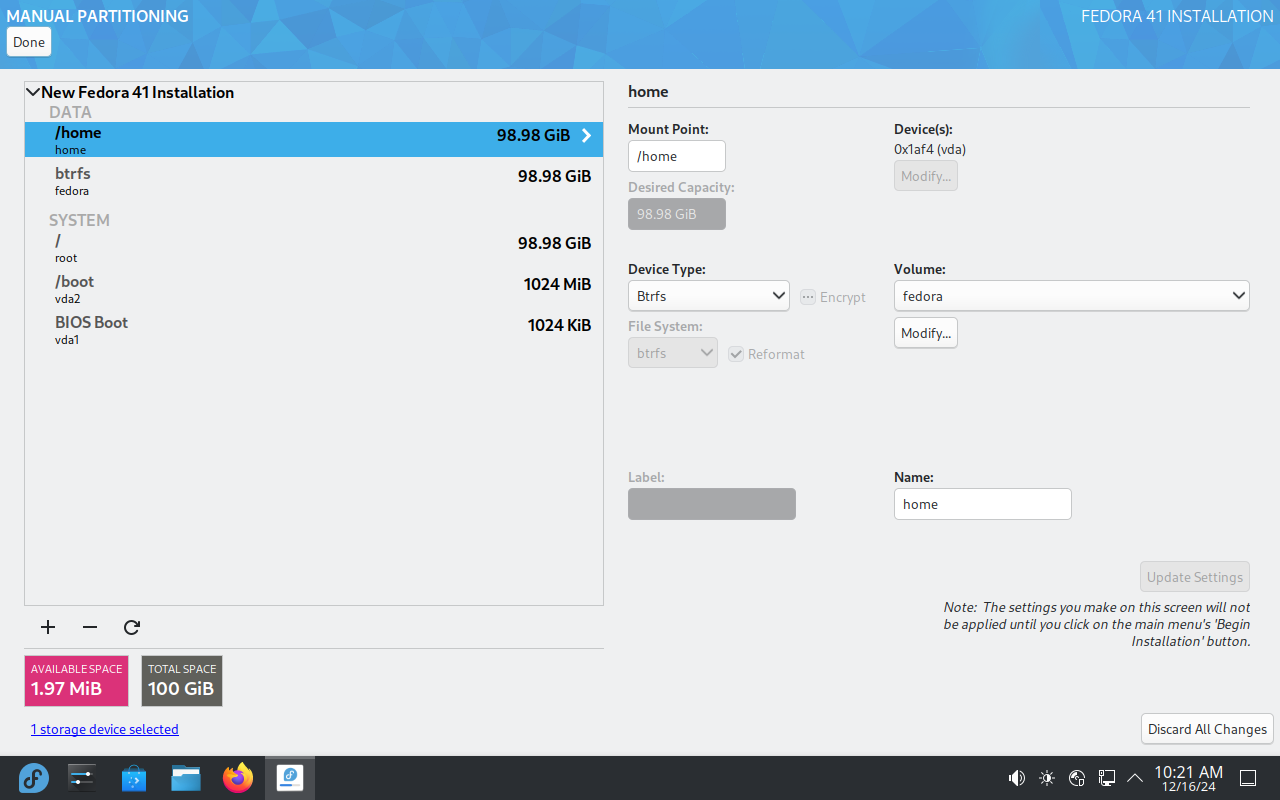
The most important step during the installation is disk configuration.
I always use the whole disk erasing whatever was there, enable
LUKS based
full disk encryption, select btrfs partitioning scheme and then let the
installer create a default configuration I can review and tweak as needed. I
insist on a separate volume for /home, but sometimes I need other changes
such as separate volume for virtual machine images.
If I were not using btrfs, I would also want to control how much disk space is
left unused for later use.
I don’t configure any additional user accounts, but I need to make sure root account is enabled and set a password for it.
Post Installation setup via Ansible
After the installation I login via text console as root and install git and ansible so that I can clone and run my ansible post installation playbook. This way I perform common boring post installation steps such as enabling rpmfusion free repository, creating user accounts or installing additional rpm packages.
This set of ansible playbook and roles serves both as a documentation and as a scripted way to perform the setup. Ansible playbooks can be actually quite readable if you care enough about that, and roles can include a README file with references to documentation and reasoning behind the configuration. Some of the roles I have there just implements a few steps taken from Fedora documentation or wiki, such as the role for kvm/libvirt based virtualization, while others cover a personalized setup, like this custom setup for a lightdm display manager.
If you are considering this approach yourself, have a look at Linux System Roles project (btw Fedora has it packaged). They provide set of general ansible roles you can parametrize via set of variables passed to it. This can save you some time spent on implementing and testing a role. I don’t use it in my post install playbook myself since I created my playbook way before this project started.
And even though the work I put into this is indeed bit higher compared to a case when I just do them manually and then write it down somewhere, I don’t need to reinstall a machine again to get the time and effort invested into this back. Just by rerunning the playbook I can check (and enforce) whether the configuration I did long time ago is still used. Sometimes I just tweak or create playbook/role to reconfigure something long after the installation, or I use some of the roles in a different context, eg. for setting up a testing virtual machine. That said, it’s worth noting that because of changes in the distribution and ansible ecosystem itself, additional maintenance is needed every now and then.
Etckeeper
That said I don’t use ansible for everything. In most cases I just edit config
files in /etc directly (or use tools like firewall-cmd which
edits files there on my behalf). Only if I conclude that the automation
effort makes sense, eg. because I will need given system change next time I
reinstall the system, I sit down to write ansible playbook or role for it.
This means that I still need to keep /etc organized, which I manage by
tracking it with git using etckeeper.
After I change something in /etc directory, I
create a dedicated commit for the change, including a description of what I’m
doing in a commit message. This way I know what, when and why I have changed
something.
An important piece of etckeeper tools is a hook for a package manager, so that
any change made in /etc during package installation, removal or update is
captured in a dedicated commit along with all relevant metadata (list of
packages, versions …).
The configuration I use is available in my
etckeeper ansible role,
but in short, I disable daily auto commits forcing myself to commit any changes
explicitly.
But using both ansible as well as etckeeper creates one problem: how to commit changes done during run of a playbook? Making one big commit for the whole run would be easy, but it will result in a commit too large to be useful. To solve this I wrote a simple etckeeper ansible callback plugin hooking ansible playbook result callbacks to create commit for each ansible task in a playbook. The only downside of this approach is that it works locally only, but it’s not a problem for my use case here.
Overall this approach has multiple benefits:
- There is a clear record of all configuration changes with additional metadata.
- Based on a commit message I can see if it comes from a default configuration, was done via my ansible playbook or manually.
- I can use standard git tools (like
git blame,git logorgit cal) to get more insight. - When I run into a problem, I can have a look what I changed recently and recheck if that can be related.
- Since easy fallback via
git checkoutorgit revertis available, I can experiment with a configuration without having to manually backup existing state. - I will notice unexpected changes performed automatically by some system component (I can’t miss this since it will leave uncommited changes) or can inspect changes which comes with new version of a package.
Another benefit of this approach is that it provides a convenient way to
archive and review old system configurations. I used to create tarballs of
/etc directory just in case I may need it later, but I almost
never used it for anything, even when I had some reason to do so. This is
because the tarball
approach lacks context (What was the thing I changed compared to the default
and why? Does it actually contain the change I’m interested in?) and
standardization (Where do I actually store it?).
Etckeeper solves all this. I can just push
current state of main branch into separate git bare repository.
Later on, when I want to revisit it on a different system, I can just fetch
this archive repository as a remote in existing etckeeper managed repo, and
then I’m able to work with it easily. For example (assuming name of the archive
remote is dione-2018):
- List commits in the archive remote:
git log --graph --oneline dione-2018/master. - Compare the archived state with the current one for a given file, eg.:
git diff dione-2018/master HEAD dnf/dnf.conf - Use particular old commit in the current
/etcrepo viagit cherry-pick.
Backup
I backup whole /home directory. On a personal machine, I don’t really care
about anything else, with exception of /etc directory, for which I maintain
etckeeper remote bare repo in /home dir.
This way, I don’t need to think about what is crucial enough for a backup,
everything in /home dir is! And it also makes recovery
planning simple. Other backup schemes can be used on top or along side of it,
but that is out of scope of this post.
This approach relies on the fact that I use dedicated home volume and a partitioning scheme which allows for quick copy-on-write snapshots so that I can make a shapshot instantly and then continue using the machine while a backup is running from a consistent state. This is helpful especially when the backup itself takes longer because of network or iops bottleneck on the receiving end.
At first I used lvm thin pools, but few years ago I moved to btrfs, so that now I can use btrfs send/receive functionality to transfer incremental snapshots to a local or remote backup device. Here I can run btrfs scrub to make sure that I still have the data.
To restore data, I will just use send/receiver again, but this time transferring data from the backup device to the machine.
Upgrading OS
I need to upgrade to a new Fedora release every half a year or so. But since a Fedora release is supported for about 13 months, I’m not forced to upgrade until I can find some time to actually do it.
Nowadays I use Fedora supported dnf system-upgrade. This means that the upgrade is handled by the package manager. First it downloads all new rpm packages and runs dnf transaction check on them (so that one can detect a package conflict before the upgrade), and then if all looks good one reboots into system-update systemd target to perform the upgrade in an isolated environment.
I used yum/dnf based upgrade long before this was polished into an official upgrade path, since I always preferred this approach over other options. Reinstalling the system just to upgrade a personal machine doesn’t feel reasonable to me.
Reinstall or Migration
Now you may wonder why do I mention reinstall when I just noted that I use dnf based upgrade. But in case of significant hardware changes (buying a whole new machine or just replacing small or dying disk with a new one) I find it easier and faster to just reinstall the system from scratch, assuming that the OS installer will detect the new hardware and set appropriate defaults. The same applies to a significant changes in storage configuration or partitioning. You may be thinking that there is no reason to change storage setup so drastically, but I did that few times, eg. when I wanted to reencrypt my LUKS volume using latest defaults or moved from lvm thin pools to btrfs.
And thanks to my ansible post installation automation and backups of home volume, this process boils down to:
- making backup of home volume
- (re)installing the system
- post install setup via ansible playbook
- recovery of home volume backup snapshot
Obviously this requires much more effort compared to the sheer dnf upgrade, but it’s manageable since it’s documented/automated. Most effort usually goes into considering new hardware or software configurations or maintenance of ansible code as I noted already.
Disaster Recovery
Let’s say a disk in my machine stops working out of sudden so that I need to buy a new one and then restore it into working condition as soon as possible. And as you have probably noticed, I have all the pieces in place to handle this via reinstall followed by a full backup recovery as explained above. Moreover since I reinstall my machine every now and then, I have the recovery procedure fully tested in real conditions. And yes, I don’t do such a test very often, it’s still way better than trying it out for the first time while recovering a machine under stress. The last thing I want to run into is that something doesn’t actually work as I thought it would.