Have you ever noticed a link pointing to a site with invalid TLS certificate in your search results? Do you consider it impossible? Contrary to my expectations it turns out that it could happen with basically any search engine. Moreover it’s also a good motivation for including canonical link element in your web pages.
Motivation
Some time after I moved my blog to current blog.marbu.eu domain in 2022, I
noticed a
weird issue. Google was indexing it under a different random looking domain
instead!
This confused me a bit at first, but eventually I fixed configuration of my
blog (and it’s web server) so that it stopped happening
and I forgot about it, assuming that this could only happen for new, small and
misconfigured websites. But recently I run into this kind of glitch
again, and since this time it’s happening on a large and established site,
I finally decided to figure out what is going on.
Example of the problem
Let’s get started with an example. Using Google I searched for “Comparison of Available Implementations of XML databases” and got the following reply.
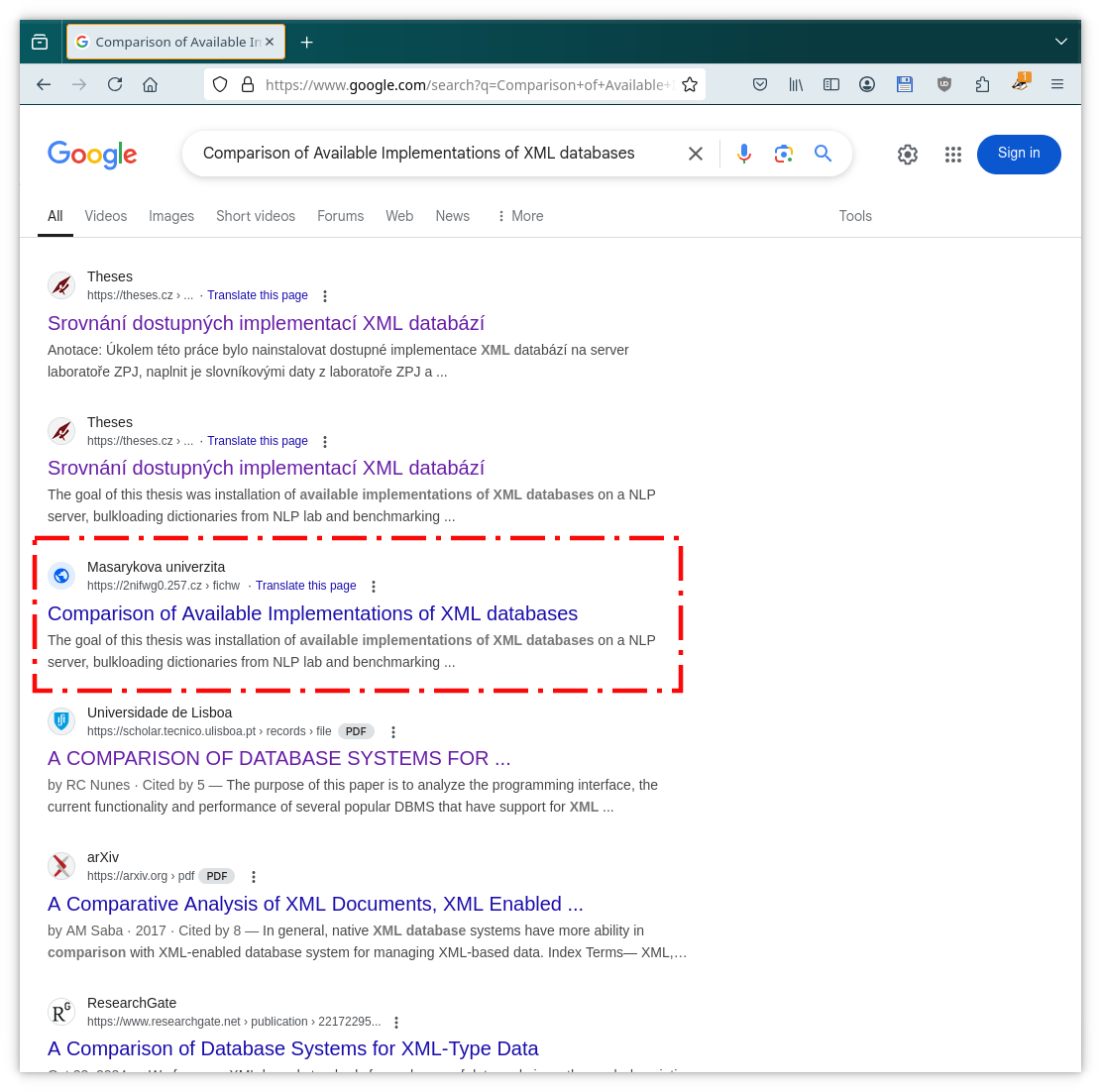
The first two results look ok, but the third one seems fishy. It looks like a
result from is.muni.cz but the domain is
2nifwg0.257.cz and
when I follow the link
I end up with SSL_ERROR_BAD_CERT_DOMAIN error (obviously).
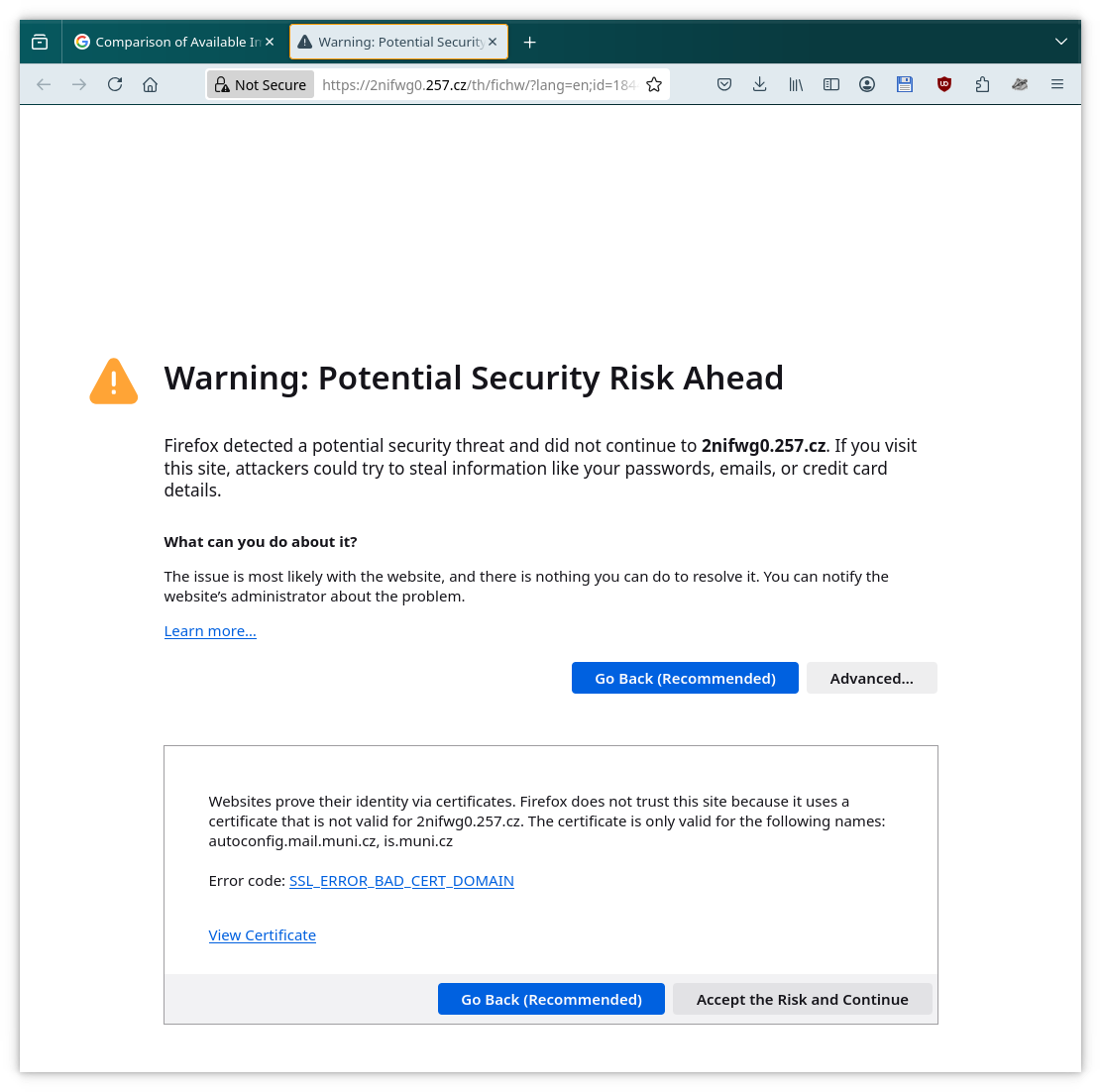
If I edit the URL and replace 2nifwg0.257.cz with is.muni.cz, I
will get to a proper page.
Another weird thing is that there is no result from is.muni.cz in the
results. But that doesn’t mean that is.muni.cz is not searchable via
Google at
all, in other cases,
one can get result from there just fine.
What is going on?
Checking the domain 2nifwg0.257.cz reveals that
it is pointing to the IP address of is.muni.cz:
$ host 2nifwg0.257.cz
2nifwg0.257.cz has address 147.251.49.10
$ host 147.251.49.10
10.49.251.147.in-addr.arpa domain name pointer is.muni.cz.
$ host is.muni.cz.
is.muni.cz has address 147.251.49.10
is.muni.cz mail is handled by 50 arethusa.fi.muni.cz.This sometimes happens when the original owner of the domain no longer cares
about it and forgets about it’s DNS entry while somebody else is assigned the
original IP address. In this case it seems to be done on purpose though. The
257.cz is a service monitoring .cz domains and it
maintains a pool of
DNS entries pointing to every globally reachable IPv4 address.
They even provide REST API for their DNS database, so that we can see
autogenerated entries for 147.251.49.10 address of is.muni.cz and indeed
find the 2nifwg0 subdomain there:
$ curl https://257.cz/adns/147.251.49.10
zkrxtu.257.cz
2nifwg0.257.cz
44bg3v27.257.cz
5-dstpe.257.cz
7obgsbl.257.cz
9c94qys.257.cz
b06tpkz.257.cz
cp4ho75.257.cz
ed25muc.257.cz
g0-ulgj.257.czSo when one tries to connect to 2nifwg0.257.cz, the is.muni.cz
server will answer and there is no other way to process the answer than to
ignore the TLS validation during the process. This suggests that Google crawler
is fetching page content even when it gets TLS errors such as
SSL_ERROR_BAD_CERT_DOMAIN.
I don’t think that it’s wrong for a crawler to ignore SSL while fetching web pages. After all one goal of a crawler is to fetch as much data as possible. The main problem is that this information seems to get lost later on. Even though Google fetched the site via domain which doesn’t match certificate of the site, it gets into Google’s production search index and in some cases, it’s even ranked higher than the actual proper domain in Google search results. This is definitely not ok. Isn’t Google supposed to use https configuration as a ranking signal? Moreover these days Google Search Console will even provide site owners with report on HTTPS usage. Google is definitely encouraging sites to use TLS widely and properly.
Another surprise waited for me when I tried to check if someone else haven’t seen such behaviour before. The first Google search result led me to a Stack Overflow question from 2017 where someone wonders why Google started indexing their page using https URL when they never intended to use SSL on the site. While such approach is questionable now as it was in 2017, it shows that the behaviour I observe is there for some time and that many people must have noticed it before.
What information does Google have here?
Google have quite a few hints that something is wrong and what is a right domain for the site in this case:
- The sheer fact that a site was crawled while getting
SSL_ERROR_BAD_CERT_DOMAINerror should be enough for Google to not include it in it’s index in the first place. - The TLS certificate of the site contains it’s
common name
(in this case
CN=is.muni.cz). - Google crawler must have fetched data from
is.muni.czdomain as well and so Google could have noticed that there are 2 sites with identical content, one of which is more popular and interlinked with the rest of the internet than the other. - Sitemap file available at
sitemap.xmland referenced inrobots.txtcontains valid URLs of the site, all starting withhttps://is.muni.cz.
What information is Google missing?
On the other hand, there is one crucial hint which Google doesn’t have in this case: canonical link element:
$ curl 'https://is.muni.cz/th/fichw/?lang=en;id=184407' 2>/dev/null | grep canonical
$Nor is this information available among HTTP headers (another place where it can be provided):
$ curl -I 'https://is.muni.cz/th/fichw/?lang=en;id=184407' 2>/dev/null | grep canonical
$That said even though in this particular case it seems clear what actual hostname of a site is, detecting a canonical URL for a page is not a simple problem in general. There is a reason why canonical link element was introduced many years ago.
What sites are prone to this?
Obviously the problem I described above can’t just happen to any site. The web server hosting the site have to provide it’s content for requests using sheer IP address as well as hostname the webserver doesn’t recognize:
$ curl -k -H "Host: example.com" 'https://147.251.49.10/th/fichw/?lang=en;id=184407' 2>/dev/null | head -7
<!DOCTYPE html>
<html class="no-js" lang="en">
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type">
<meta content="IE=edge" http-equiv="X-UA-Compatible">
<meta content="width=device-width, initial-scale=1" name="viewport">
<meta content="Srovnání dostupných implementací XML databází" name="citation_title">This mean that it’s either the only site the web server is hosting or it’s a default virtual host. Such web server configuration is completely valid and there is nothing wrong with it. It just happens that if your configuration is different, this issue can’t possibly happen on your site.
How did I fixed it for my blog?
When I noticed this problem again in August 2023 (eg. in this
archive.today’s
snapshot
you can see results from my blog shown under 29g78bs.257.cz instead
of blog.marbu.eu domain) I decided to finally introduce canonical url link
element to every page of my
blog.
Shortly after that I also reconfigured my web sever so that
www.marbu.eu is the default virtual host instead.
After this, the problem eventually disappear.
Whether you want to do this as well depends. Even for a small personal site, it’s worth the consideration, since you avoid bots discovering and indexing the site early. And even later on, a small site owner may find it handy that traffic from large pool of bots trying stupid attack vectors against the whole IPv4 address range are not polluting webserver logs of your blog (chances are that you will receive more hits from such bots than from actual readers).
Inspecting subdomains of 257.cz
When I realized that for both my blog and is.muni.cz, the domain Google
sometimes presented in search results instead of the original domain was a
subdomain of 257.cz service, I decided to check what will I get from Google
when use
site:257.cz query
(archive.org capture from 2025-03-23).
And as expected, Google provided me with a long list of results. Most were
written in Czech language and hosted on .cz domain.
This means that there are quite lot of sites which are prone to this issue.
Inspecting TXT record of the domain shows that the owner is using Google Search Console:
$ host -t TXT 257.cz
257.cz descriptive text "google-site-verification=B2jXH3sfzArrYqOrZBupgE5xLjc-Uxz3Zd2fuHp8ZPE"
257.cz descriptive text "v=spf1 include:_spf.shy.cz include:_spf.google.com ~all"That means that the 257.cz service may have some access to the stats about how often a result from their subdomain pointing to another TLS site ends up in Google search result. But I’m not sure if they are using this particular type of data for anything.
Checking other search engines
We can try the query site:257.cz on other search engines as well to quickly
verify whether they also behave in the same way when we directly ask for it.
Here it’s important to note that a negative results is not good enough evidence to conclude that given search engine doesn’t ignore TLS during indexing (the results may not be included for other reasons), while a positive result shows that this definitely happens.
| Search Engine | Country | Result for site:257.cz query contains broken TLS sites? |
|---|---|---|
| Seznam | CZ | yes (one needs to go through few pages to run into one) |
| Bing | US | yes |
| DuckDuckGo | US | yes |
| ChatGPT | US | yes |
| Marginalia | SE | no results at all (site not indexed) |
| Mojeek | UK | no results at all |
| Brave | US | yes |
| Yandex | RU | yes |
| Baidu | CN | yes (there is only a single result) |
| Sogou | CN | yes (there is only a single result) |
Basically every search engine I tried provided some sites with broken TLS unless it showed no results at all. This realy surprised me. It suggests that this is not a bug in particular search engine, but a common deliberate practice followed by basically all search engines.
That said I have never seen results affected with this problem as a result of a normal looking query (such as the one I started this post with). And it doesn’t mean that it couldn’t happen for other search engines as well, as this behaviour is rare and can’t be universally reproduced even on Google. We just don’t know.
Yet I have no idea why would anyone want to implement such behaviour. I understand why the crawlers ignore certificates (I’m “guilty” of writing such a crawler myself). But I would expect that the data fetched in this way will get to the index only in few special cases when it makes sense for the owners of the search engine. I can imagine somewhat valid reasoning to do so for eg. self signed certificates, certs signed by CA trusted only in regions the search engine finds important, certs recently expired … But I see no good reason to wave this off when the problem is in mismatch between a CN of the cert and a hostname of the site. On the other hand since this kind of problem is indeed very rare, it seems that some TLS validation is definitely happening, otherwise we would run into this much more often. So in the end, this looks like a discrepancy between my naive assumptions and actual design of real search engines.
Now I want an option to directly ask a search engine for search without TLS or with TLS broken in a particular way. It could be interesting to see how that influences the search results. And in other cases it could help me if I could rule out sites without TLS, with broken TLS or signed by certificate authorities I don’t like. Maybe at least Shodan supports this in some way? But Shodan is not a general search engine.
What to take from this?
Unless you really test them, some of your assumptions about validation 3rd party services do may be wrong, no matter how reasonable your assumption seem to you. Especially if the behaviour is not part of the contract nor documented.
The fact that search engines ignore TLS so that results with serious issues can in some cases end up in search results is still very surprising to me.
In any case, it’s a good motivation for including canonical URLs in your web pages and to pay more attention to configuration of your web server to avoid search engines to go crazy.